Sample Midterm¶
Things to know for the midterm
- Bayes' rule, sum and product rules of probability, expectations
- Conditioning, normalization, marginalization
- Exponential family distributions, deriving their sufficient statistics and maximum likelihood
- Relationship between graphical model and factorization of joint distribution
- Determining conditional independence
- Variable Elimination and complexity of inference
Question 1¶
Recall that the definition of an exponential family model is:
where
- \(\eta\) are the parameters
- \(T(x)\) are the sufficient statistics
- \(h(x)\) is the base measure
- \(g(\eta)\) is the normalizing constant
Consider the univariate Gaussian, with mean \(\mu\) and precision \(\lambda = \frac{1}{\sigma^2}\)
What are \(\eta\) and \(T(x)\) for this distribution when represented in exponential family form?
Solution
Start by expanding the terms in the exponent
from here, we can rearrange the exponent into \(\eta^TT(x)\)
where
- \(\eta^T = \begin{bmatrix}\lambda \mu & -\frac{\lambda}{2}\end{bmatrix}\)
- \(T(x) = \begin{bmatrix}\sum_{i=1}^N x_i\\ \sum_{i=1}^N x_i^2\end{bmatrix}\)
Question 2¶
Consider the following directed graphical model:
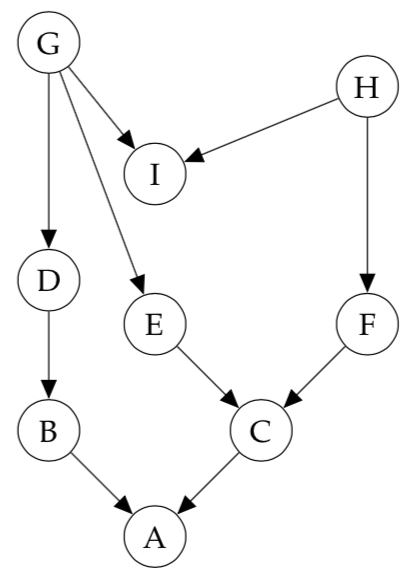
a) List all variables that are independent of \(A\) given evidence on \(B\)
Solution
By Bayes' Balls, no variables are conditionally independent of \(A\) given evidence on \(B\).
b) Write down the factorized normalized joint distribution that this graphical model represents.
Solution
c) If each node is a discrete random variable in \(\{1, ..., K\}\) how many distinct joint states can the model take? That is, how many different configurations can the variables in this model be set?
Solution
For each node (random variable) there is \(k\) states. There are \(k^n\) possible configurations where \(k\) is the number of states and \(n\) the number of nodes (\(x_i\))
Question 3¶
Consider the Hidden Markov Model
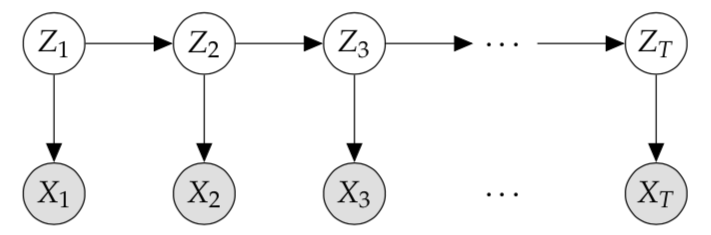
Assume you are able to sample from these conditional distributions, i.e.
Write down a step-by-step process to produce a sample observation from this model, i.e. \((x_1, x_2, x_3, ..., x_T)\) in terms of samples from the individual factors.
Solution
We want to sample a sequence of observations \(x_1, x_2, x_3, ..., x_T\) from the model according to
since observations \(x_t\) are independent of one another. Notice that this forms a chain, with probability
Step-by-step
- Start with \(t=1\)
- Sample \(z_t\) according to \(z_t \sim p(z_1) \prod_{i=t}^{t + 1} p(Z_i | z_{i-1})\)
- Given the sampled \(z_t\), sample \(x_t\) according to \(x_t \sim \ p(X_t | z_t)\)
- Increment \(t\) by 1
- Repeat steps 2-4 until \(t=T\)
Question 4¶
Consider the graphical model
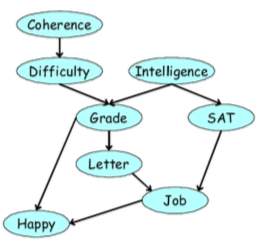
a) Write down the factorization of the joint distribution given by this graphical model.
Solution
b) Use the Variable Elimination algorithm to find \(p(J)\) with the ordering \(\prec \{G, I, S, L, H, C, D\}\). What is the complexity of the VE algorithm with this ordering?
Solution
This is a variable elimination ordering over \(m=8\) factors each with \(k\) states. The sum with the largest number of variables participating has \(N_\text{max} = 6\) so the complexity is
b) Use the Variable Elimination algorithm to find \(p(J)\) with the ordering \(\prec \{D,C,H,L,S,I,G \}\). What is the complexity of the VE algorithm with this ordering?
Solution
This is a variable elimination ordering over \(m=8\) factors each with \(k\) states. The sum with the largest number of variables participating has \(N_\text{max} = 4\) so the complexity is
Question 5¶
Consider the following directed graphical model:
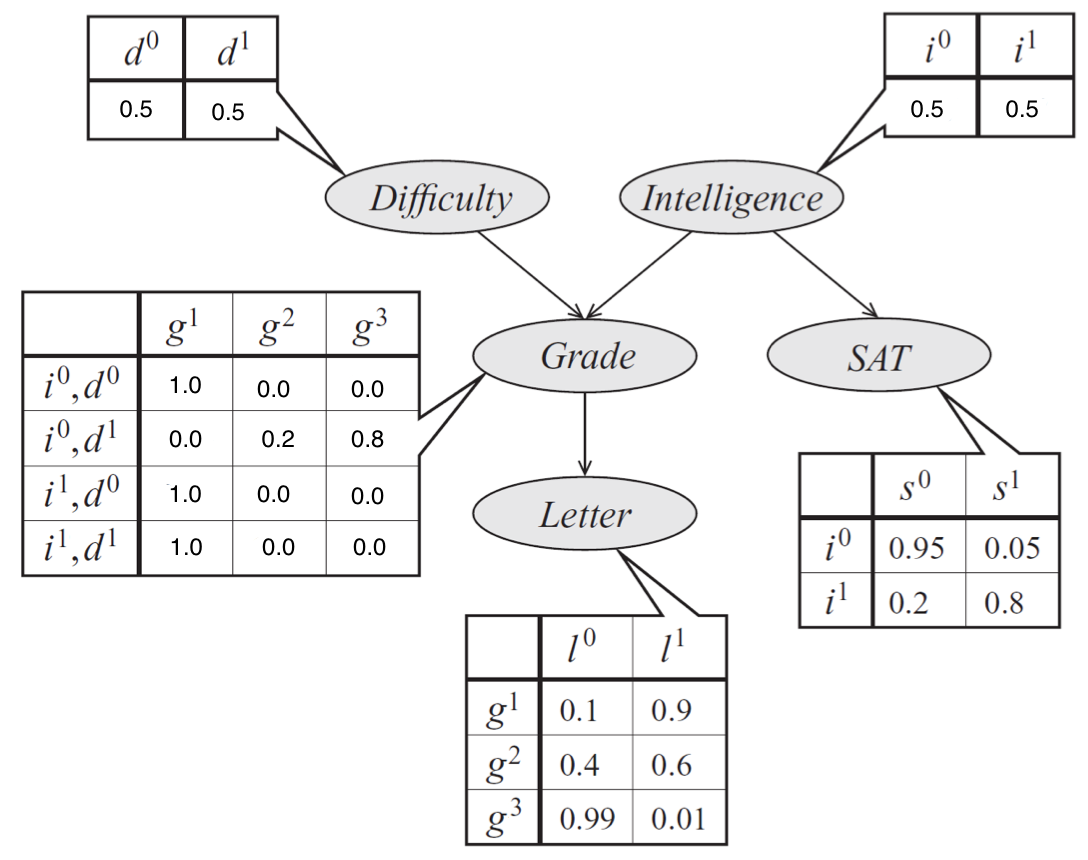
a) Write the a table giving joint distribution of Difficulty \(D\) and Intelligence \(I\).
Solution
Variables \(I\) and \(D\) are marginally independent, so their joint distribution factorizes into \(P(I,D) = P(I)P(D)\)
| I | D | P(I,D) |
|---|---|---|
| 0 | 0 | 0.25 |
| 0 | 1 | 0.25 |
| 1 | 0 | 0.25 |
| 1 | 1 | 0.25 |
b) Write the table giving the joint conditional distribution of Difficulty \(D\) and Intelligence \(I\) given that Grade = 1.
Solution
Because they're leaf nodes, we can ignore Letter and SAT. The rest of the answer can be computed using the definition of conditional distributions.
c) What is the probability of Intelligence given that Grade = 1?
d) What is the probability of Intelligence given that Grade = 1 and Difficulty = 0?